
Ap statistics chapter 2 test – Embarking on a journey through AP Statistics Chapter 2, we delve into the captivating realm of data representation and analysis. Understanding the art of organizing and interpreting data is paramount, and this chapter provides the essential tools to unlock its potential.
Prepare to unravel the mysteries of central tendency, variability, probability distributions, and sampling distributions as we navigate this fascinating chapter together.
Data Representation
Organizing data is crucial for analysis as it allows us to identify patterns, trends, and relationships within the data. Data can be represented in various ways, each with its advantages and disadvantages.
Tables
Tables are a structured way to organize data into rows and columns, making it easy to compare and sort data. Advantages include clear organization and ease of reading. However, tables can be cumbersome for large datasets and may not effectively display complex relationships.
Graphs
Graphs provide a visual representation of data, making it easier to identify trends and patterns. Common types of graphs include bar charts, line charts, and scatterplots. Graphs are effective for visualizing relationships and distributions, but they may require more interpretation than tables.
Charts
Charts are similar to graphs but use symbols or icons to represent data. They are commonly used to compare data across different categories or to show proportions. Advantages include visual appeal and ease of comparison, but they may not be as precise as tables or graphs.
Measures of Central Tendency
In statistics, measures of central tendency are used to describe the “average” or “typical” value of a data set. The three most common measures of central tendency are mean, median, and mode.
Mean
The mean is the sum of all the values in a data set divided by the number of values. It is also known as the arithmetic average.
To calculate the mean, add up all the values in the data set and then divide by the number of values. For example, if the data set is 1, 3, 5, 7, 9, the mean is (1 + 3 + 5 + 7 + 9) / 5 = 5.
After a quick review of AP Statistics Chapter 2 test, I stumbled upon an interesting resource that could help me visualize the political landscape of Africa in 1914. The africa in 1914 map worksheet provides a detailed overview of the continent’s borders and colonial divisions during that time.
This knowledge could enhance my understanding of historical events discussed in the AP Statistics Chapter 2 test, particularly those related to data collection and analysis in the context of colonialism.
The mean is a good measure of central tendency when the data is normally distributed. However, it can be misleading if the data is skewed.
Median
The median is the middle value in a data set when the values are arranged in order from smallest to largest. If there are two middle values, the median is the average of the two middle values.
To calculate the median, first arrange the data set in order from smallest to largest. Then, if there is an odd number of values, the median is the middle value. If there is an even number of values, the median is the average of the two middle values.
For example, if the data set is 1, 3, 5, 7, 9, the median is 5.
The median is a good measure of central tendency when the data is skewed.
Mode
The mode is the value that occurs most frequently in a data set. A data set can have more than one mode.
To calculate the mode, simply find the value that occurs most frequently in the data set. For example, if the data set is 1, 3, 5, 5, 7, 9, the mode is 5.
The mode is a good measure of central tendency when the data is skewed.
Measures of Variability

Measures of variability, such as range, variance, and standard deviation, quantify the spread or dispersion of data. They help describe how much the data values differ from the central tendency.
Range
The range is the simplest measure of variability. It is calculated by subtracting the smallest value from the largest value in the data set.
- Formula:Range = Maximum Value – Minimum Value
- Interpretation:The range indicates the overall spread of the data but can be sensitive to outliers.
Variance
Variance is a more sophisticated measure of variability that takes into account the distance of each data point from the mean. It is calculated by finding the average of the squared differences between each data point and the mean.
- Formula:Variance = Σ(Xi – μ)² / (n – 1)
- Interpretation:Variance measures the average squared deviation from the mean. A larger variance indicates greater variability.
Standard Deviation
Standard deviation is the square root of variance. It is expressed in the same units as the data and provides a more intuitive measure of variability.
- Formula:Standard Deviation = √Variance
- Interpretation:Standard deviation measures the typical distance of data points from the mean. A larger standard deviation indicates greater variability.
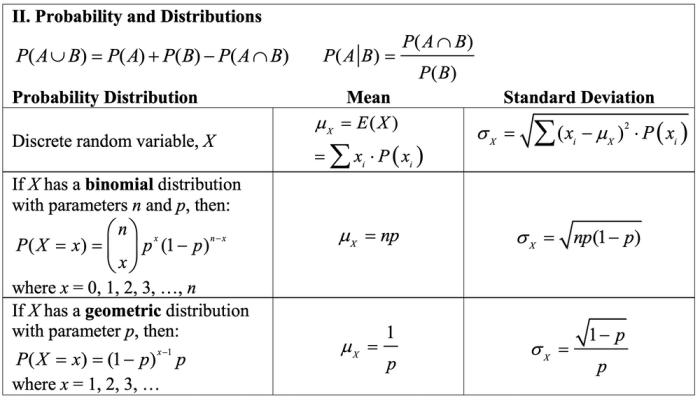
Probability Distributions
A probability distribution is a function that assigns a probability to each possible outcome of a random variable. It describes the likelihood of each outcome occurring.
There are two main types of probability distributions: discrete and continuous.
Discrete Probability Distributions
A discrete probability distribution is one in which the random variable can only take on a finite number of values. For example, the number of heads in a coin toss can only be 0 or 1.
Continuous Probability Distributions
A continuous probability distribution is one in which the random variable can take on any value within a specified range. For example, the height of a person can be any value between 0 and 2 meters.
Common Probability Distributions, Ap statistics chapter 2 test
There are many different types of probability distributions, each with its own unique characteristics. Some of the most common probability distributions include:
- Binomial distribution
- Normal distribution
- Poisson distribution
- Exponential distribution
Sampling Distributions: Ap Statistics Chapter 2 Test

A sampling distribution is a probability distribution of a statistic calculated from all possible samples of a given size from a population. It provides information about the distribution of the sample statistic, such as its mean, variance, and standard deviation.
A population is the entire group of individuals or objects being studied, while a sample is a subset of the population. Sampling is the process of selecting a sample from the population. It is important in statistical inference because it allows us to make inferences about the population based on the sample.
Sampling Distribution of the Mean
The sampling distribution of the mean is the probability distribution of the sample means of all possible samples of a given size from a population. The mean of the sampling distribution is equal to the mean of the population, and the standard deviation of the sampling distribution is equal to the standard deviation of the population divided by the square root of the sample size.
FAQ Overview
What is the importance of organizing data before analysis?
Organizing data allows us to identify patterns, trends, and relationships more easily, leading to more accurate and meaningful conclusions.
Can you explain the difference between mean, median, and mode?
Mean is the average of all values in a dataset, median is the middle value when arranged in ascending order, and mode is the value that occurs most frequently.
How is standard deviation used to measure variability?
Standard deviation quantifies the spread of data points around the mean, indicating how much the data values deviate from the central value.
